
티스토리 뷰
지인짜 오랜만에 블로그 글을 쓴다. 마지막 글을 쓴지 거진 4개월이 지났는데... 그동안 바빴다면 바빴고, '이번 주말에는 그동안 공부했던 것 정리해서 글 좀 써야지' 결심했던 것들을 미루고 미루다가 지금이 되었다... 암튼 이제 조금 여유가 생겨서 그동안 공부했던 것들을 조금씩 정리할 것이다.
회사에서는 데이터 접근 기술로 JPA가 아닌 MyBatis를 사용하고 있다. 딱히 불만은 없고 오히려 SQL에 더 친숙해지고 쿼리 튜닝도 접할 기회가 많아 좋기도 하지만, JPA를 더 공부하고 싶어서 학교 창업 동아리 소속으로 진행하고 있는 사이드 프로젝트에서는 JPA를 사용하고 있다. 역시 책으로 공부하는 것보다 프로젝트를 진행해보니, 처음 보는 문제를 맞닥뜨리면서 새롭게 알게 되는 것들이 있다. JPA 그래도 어느 정도 알고 있다고 생각했는데 착각은 금물이다.
각설하고, 프로젝트를 진행하면서 양방향 매핑은 '게시글 - 댓글', '병원 - 의사'와 같이 연관관계가 긴밀한 것들, 강한 것들에만 매핑 관계를 맺어주고 웬만하면 단방향 매핑으로 구현해왔다. 따라서, User, UserProfile, UserPrivacy 엔티티가 있을 때, UserProfile → User, UserPrivacy → User 엔티티 방향으로만 단방향 연관관계를 생성해주었다. 따라서 User 엔티티와 매핑되는 테이블은 부모 테이블이, UserProfile, UserPrivacy 테이블과 매핑되는 테이블은 자식 테이블이 된다.
여기서 부모 테이블은 다른 테이블과의 관계에서 상위에 있는 테이블로, 부모 테이블은 주로 기본 데이터를 저장한다. 반면 자식 테이블은 다른 테이블과의 관계에서 하위에 있는 테이블로, 부모 테이블의 주 키(primary key)를 외래 키(foreign key)로 참조하여 부모 테이블과의 관계를 맺으며 추가적인 데이터를 저장한다. 이때 부모 테이블의 외래키를 자식 테이블의 주 키로 사용할 건지 여부에 따라 식별/비식별 관계로 정의할 수 있는데, 오늘의 주제에서는 약간 벗어나므로 자세한 내용은 다음 글을 참고하시길.
프로젝트를 진행하며 만난 문제상황은 다음과 같다.
기존의 UserProfile → User, UserPrivacy → User로의 단방향 연관관계 뿐만 아니라 User → UserProfile, User → UserPrivacy 로의 양방향 연관관계가 추가되었다. (여기서 UserProfile, UserPrivacy가 외래키를 관리하므로 연관관계 주인) 이때 userRepository.findById(userId); 로 User 엔티티를 조회하는 경우 분명 UserProfile, UserPrivacy 엔티티에 대한 fetch 설정은 LAZY 로딩으로 설정했음에도 불구하고 EAGER 로딩처럼 동작하는 것이었다. (즉 user, user_profile, user_privacy 테이블에 대한 select 쿼리가 각각 발생함)
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class User extends BaseTimeEntity {
@Id
@GenericGenerator(name = "uuid-generator", type = com.project.foradhd.global.util.UUIDGenerator.class)
@GeneratedValue(generator = "uuid-generator")
@Column(name = "user_id", columnDefinition = "varchar(32)")
private String id;
//..
@OneToOne(mappedBy = "user", fetch = FetchType.LAZY) //lazy 로딩 설정
private UserProfile userProfile;
@OneToOne(mappedBy = "user", fetch = FetchType.LAZY) //lazy 로딩 설정
private UserPrivacy userPrivacy;
//...
}@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class UserProfile extends BaseTimeEntity {
@Id
@GenericGenerator(name = "uuid-generator", type = com.project.foradhd.global.util.UUIDGenerator.class)
@GeneratedValue(generator = "uuid-generator")
@Column(name = "user_profile_id", columnDefinition = "varchar(32)")
private String id;
@OneToOne(fetch = FetchType.LAZY) //lazy 로딩 설정
@JoinColumn(name = "user_id")
private User user;
}@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class UserPrivacy extends BaseTimeEntity {
@Id
@GenericGenerator(name = "uuid-generator", type = com.project.foradhd.global.util.UUIDGenerator.class)
@GeneratedValue(generator = "uuid-generator")
@Column(name = "user_privacy_id", columnDefinition = "varchar(32)")
private String id;
@OneToOne(fetch = FetchType.LAZY) //lazy 로딩 설정
@JoinColumn(name = "user_id")
private User user;
}[Hibernate]
select
u1_0.user_id,
u1_0.created_at,
u1_0.deleted,
u1_0.deleted_at,
u1_0.email,
u1_0.is_verified_email,
u1_0.last_modified_at,
u1_0.role
from
user u1_0
where
u1_0.user_id=?
[Hibernate]
select
up1_0.user_privacy_id,
up1_0.age_range,
up1_0.birth,
up1_0.created_at,
up1_0.gender,
up1_0.last_modified_at,
up1_0.name,
up1_0.user_id
from
user_privacy up1_0
where
up1_0.user_id=?
[Hibernate]
select
up1_0.user_profile_id,
up1_0.created_at,
up1_0.for_adhd_type,
up1_0.last_modified_at,
up1_0.nickname,
up1_0.profile_image,
up1_0.user_id
from
user_profile up1_0
where
up1_0.user_id=?
왜 그런지 이유를 알아보기에 앞서 JPA의 구현체인 하이버네이트에서는 LAZY 로딩이 어떤 방식으로 동작하며, 이러한 동작 방식이 왜 @OneToOne 양방향 매핑에서 연관관계 주인이 아닌 엔티티를 조회 시 LAZY 로딩이 동작하지 않도록 하는지 알아보자.
하이버네이트의 FetchType.LAZY 동작 방식

UserProfile 조회 시 매핑된 User 엔티티의 참조 클래스를 먼저 확인해보자. User.class 일 것이라 예상했지만 이상한 $HibernateProxy$... 타입이 붙어있다. 즉 실제 User 클래스의 객체가 아닌 가짜, 프록시 객체를 참조하고 있는 것이다. 그렇다면 프록시란 무엇일까?
프록시란?
프록시는 '대리', ‘대신하다‘라는 의미를 가지고 있는 단어로, 프록시 객체는 동작을 대신해주는 가짜 객체라 볼 수 있다. Mock 객체 처럼 단순히 가짜 객체로만 존재하기 보다는, 내부에 실제 객체에 대한 참조를 보관하여 프록시 객체를 통해 실제 객체에 접근할 수 있다. 또한 위에서 디버깅했을 때 프록시 객체의 클래스 타입은 User$HibernateProxy$U0KnkqF4였었다. 해당 클래스는 실제 클래스의 자식 클래스로, 이러한 특징으로 실제 객체 타입 자리에 프록시 객체가 들어가도 문제가 없는 것이다. 따라서 연관관계에 있는 엔티티 참조에 실제 객체가 들어있든, 프록시 객체가 들어있든 신경쓰지 않고 사용할 수 있는 것이다.

lazy 로딩과 프록시
하나의 엔티티 조회 시 연관된 엔티티를 모두 조회한다면, DB에 불필요한 select 쿼리가 여러 번 발생하게 된다. 따라서 연관 엔티티들을 모두 조회하기 보다는 필요한 연관관계만 조회해올 수 있도록 JPA는 lazy 로딩 이라는 것을 지원한다. 직역하면 게으른 로딩으로 연관된 엔티티에 대한 조회를 실제 사용시점까지 미루는 것을 말한다.
JPA 구현체 중 하나인 하이버네이트는 lazy 로딩의 구현 방식으로 프록시를 사용한다. (실제 JPA 명세에 지연 로딩의 구현 방법은 정의되어 있지 않고, 구현체에 이를 위임한다고 한다.) 즉 특정 엔티티 내 연관관계에 있는 엔티티의 FetchType이 LAZY로 설정되어 있다면, 해당 엔티티 조회 시 연관관계 엔티티의 참조에는 실제 객체가 아닌 프록시 객체가 주입되는 것이다. 그리고 실제 객체를 사용하는 시점에 DB에서 데이터를 조회한다.
프록시 초기화
'DB에서 데이터를 조회하여 프록시 객체 내부의 실제 객체에 대한 참조를 초기화하는 것'을 프록시 초기화 라고 한다. 실제로 연관된 엔티티의 id가 아닌 값 조회 시 DB에 쿼리가 나가 프록시가 초기화된다. 이때 프록시 객체 자체가 실제 객체로 바뀌는 것 이 아닌 프록시 객체 내부의 실제 객체에 대한 참조가 초기화 되는 것이다. 이후 초기화된 프록시 객체를 통해 실제 객체에 접근하여 값을 조회하게 된다.
실제 아래 코드에서 UserProfile 내 매핑되는 엔티티인 User 객체의 id 조회 시에는 select 쿼리가 발생하지 않지만, email 조회 시 DB에 실제 select 쿼리가 나가게 된다.
[Hibernate]
select
up1_0.user_profile_id,
up1_0.created_at,
up1_0.for_adhd_type,
up1_0.last_modified_at,
up1_0.nickname,
up1_0.profile_image,
up1_0.user_id
from
user_profile up1_0
where
up1_0.user_id=?
userProfile.getUser().getId() = bf7b0c5ed770434d837dc0f9ecb9b44b -- User의 id 조회 시에는 select 쿼리 발생X
[Hibernate]
select
u1_0.user_id,
u1_0.created_at,
u1_0.deleted,
u1_0.deleted_at,
u1_0.email,
u1_0.is_verified_email,
u1_0.last_modified_at,
u1_0.role
from
user u1_0
where
u1_0.user_id=?
userProfile.getUser().getEmail() = jkde7721@gmail.com -- User의 id가 아닌 email 조회하기 위해 user 테이블에 대한 select 쿼리 발생
양방향 @OneToOne에서 왜 LAZY 동작 안함?
모든 @OneToOne 관계에서 lazy 로딩이 동작하지 않는 것은 아니고, 정확히 말하면 양방향 @OneToOne에서 연관관계 주인이 아닌 엔티티를 조회할 경우 연관된 엔티티가 lazy 로딩되지 않고 eager 로딩된다. 예를 들어 앞의 예제에서 UserProfile, UserPrivacy 엔티티를 조회할 때에는 lazy 로딩이 동작하는 반면, User 엔티티 조회 시에는 연관된 UserProfile, UserPrivacy가 eager 로딩으로 조회된다. 왜 그럴까? 차차 살펴보자.
일단 연관된 엔티티의 참조값은 null이거나 프록시 객체일 수 있다.(FetchType이 LAZY인 경우) 매핑된 엔티티가 null이라면 연관관계가 없다는 것을, 프록시 객체라면 연관관계가 분명히 존재한다는 것을 의미한다.
영속성 컨텍스트 내 프록시 객체
이때 영속화된 엔티티는 영속성 컨텍스트 내부에서 key-value 형태로 관리되며, key는 엔티티의 id, value는 엔티티 객체 자체이다. 따라서 영속성 컨텍스트 내부에서 관리되는 객체가 실제 객체이든, 프록시 객체이든 id가 필요하다. 즉 lazy 로딩에서 연관된 엔티티 참조인 프록시 객체도 영속성 컨텍스트에서 관리되며 이를 위해 해당 엔티티의 id값은 알고 있어야 한다는 뜻이다.
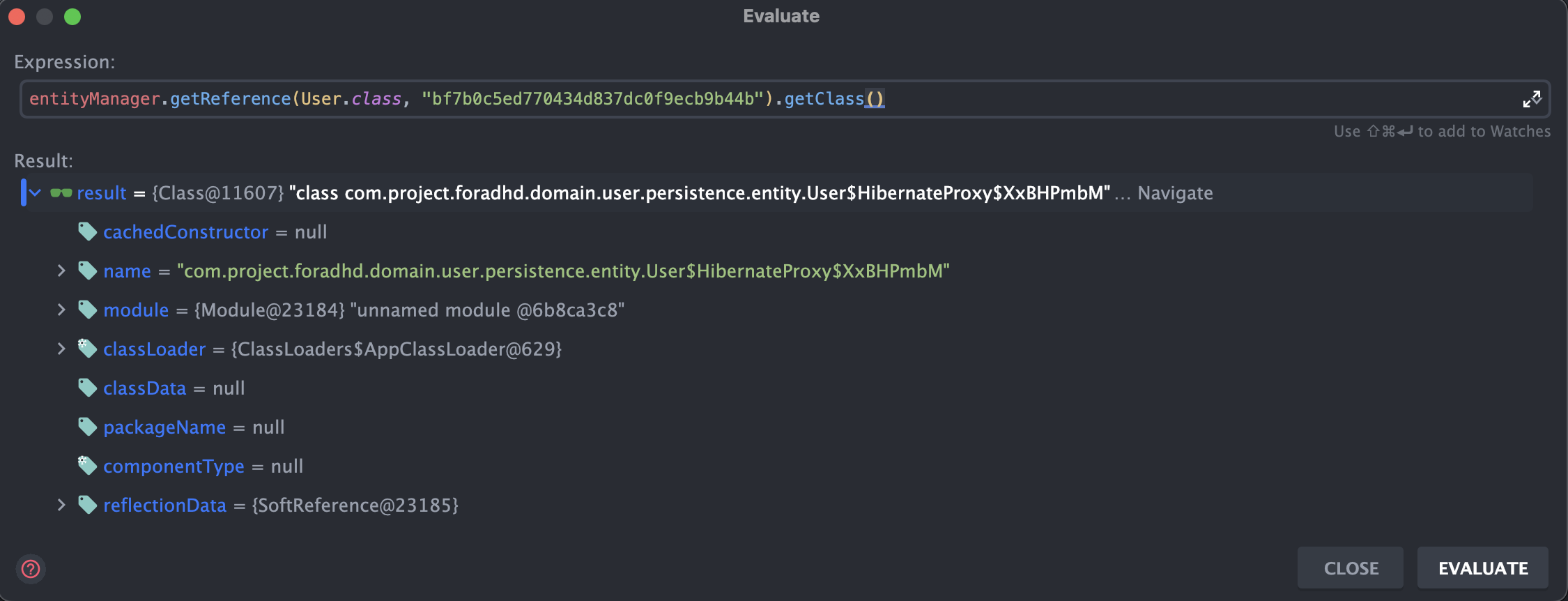
실제 userProfileRepository.findByUserId(userId); 로 UserProfile 객체 조회 시 연관된 엔티티인 User 객체는 영속성 컨텍스트에서 프록시 객체로서 관리되고 있다. (getReference 메소드의 두번째 인자로 전달된 값은 User의 id이다.)
연관관계 주인인 엔티티는 실제 매핑되는 테이블에서 직접 외래키를 관리하기 때문에 외래키 컬럼이 null이라면 매핑된 엔티티 참조에 null을, 외래키가 존재한다면 해당 외래키를 id로 가지는 프록시 객체를 설정해준다. 즉 자신의 테이블만을 조회함으로써 연관된 엔티티의 존재 여부를 알 수 있는 것이다.
그러나 연관관계 주인이 아닌, mappedBy가 선언된 엔티티를 조회 시에는 연관된 엔티티의 id를 자기 테이블만으로는 알 길이 없다. (ex. user 테이블에서 user_profile, user_privacy 테이블에 대한 외래키를 관리하고 있지 않기 때문) 따라서 연관된 엔티티의 id를 알기 위해 항상 eager 로딩이 발생하는 것이다. (user_profile, user_privacy 테이블을 모두 조회해야 연관된 엔티티를 null 또는 프록시 객체로 설정할 수 있음)
항상 null? 항상 프록시 객체?
연관된 엔티티의 id를 모르겠으면 일단 항상 null로 설정하면 안되나? 의문이 들 것이다. 앞서 말했듯 엔티티 참조 값이 null이라는 것은 엔티티가 존재하지 않음을 의미한다. 연관 엔티티가 존재할 수도 있는데 null로 설정하는 것은 올바르지 않다.
그럼 차라리 항상 프록시로 설정 후 프록시의 id 값을 null로 설정하면 안되나? 프록시 객체가 설정되었다는 것은 엔티티가 존재함을 의미하며, 이 또한 연관 엔티티가 존재하지 않을 수도 있는데 프록시 객체로 설정하는 것은 올바르지 않다. 또한 영속성 컨텍스트에서 관리되기 위해서는 일단 id가 필수이다.
즉 @OneToOne 양방향 매핑에서 lazy 로딩이 동작하지 않는 것은 연관된 엔티티 참조에 대한 표현법이 null, 프록시 객체 이렇게 2가지만 존재해서 발생하는 문제이다. 만약 '엔티티가 존재할 수도, 존재하지 않을 수도 있다'는 또 다른 표현법이 추가된다면 lazy 로딩이 가능할 수도 있겠다.
지금까지의 내용을 정리하자면 다음과 같다.
- @OneToOne 양방향 매핑에서 lazy 로딩이 동작하지 않는 경우는 연관관계 주인이 아닌 엔티티를 조회하는 경우
- 매핑되는 엔티티의 id를 알기 위해 항상 eager 로딩 발생
@OneToMany에서는 LAZY 동작하던데?
한편 양방향 @OneToMany, 예를 들어 team - member 관계에서 Team 엔티티를 조회하는 경우에는 List<Member> memberList 에 대한 lazy 로딩이 동작한다. 앞서 말한대로라면 team 테이블은 member 테이블에 대한 외래키를 관리하고 있지 않으므로 lazy 로딩이 동작하지 않아야 한다. 그러나 이 경우엔 lazy 로딩이 가능하다. 왜 그럴까?
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Team {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "team_id")
private Long id;
private String name;
@OneToMany(mappedBy = "team", fetch = FetchType.LAZY, cascade = CascadeType.ALL, orphanRemoval = true)
List<Member> memberList = new ArrayList<>();
//연관관계 편의 메소드
public void updateMemberList(List<Member> memberList) {
this.memberList = memberList;
this.memberList.forEach(member -> member.updateTeam(this));
}
}@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "member_id")
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
public void updateTeam(Team team) {
this.team = team;
}
}[Hibernate]
select
t1_0.team_id,
t1_0.name
from
team t1_0
where
t1_0.team_id=?
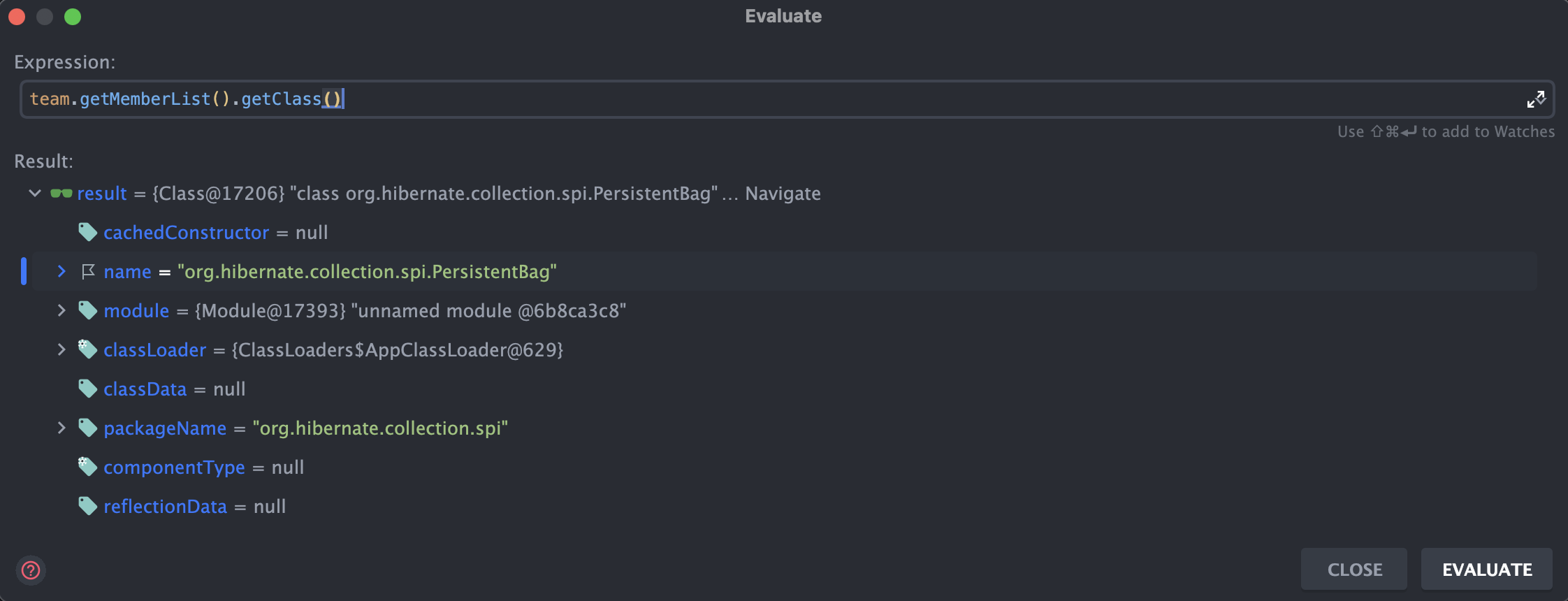
team.getMemberList().getClass() = class org.hibernate.collection.spi.PersistentBag
[Hibernate]
select
ml1_0.team_id,
ml1_0.member_id,
ml1_0.name
from
member ml1_0
where
ml1_0.team_id=?
team.getMemberList().size() = 3 -- memberList 컬렉션의 사이즈를 조회하기 위해 member 테이블에 대한 select 쿼리 발생
위와 같은 매핑 관계에서 Team 엔티티만을 조회 시 lazy 로딩으로 설정했으므로 member 테이블에 대한 select 쿼리는 발생하지 않았지만, memberList 필드의 size를 조회하거나 각 Member 엔티티에 접근 시에는 member 테이블에 대한 select 쿼리가 발생한다. 여기서 주목해야 할 건 memberList 참조 클래스 타입이 PersistentBag 라는 것이다.
Hibernate의 Collection 매핑 클래스 PersistenetBag
@OneToMany에서는 매핑되는 엔티티를 Collection 타입으로 관리하며, 하이버네이트에서는 컬렉션 타입을 org.hibernate.collection.spi.PersistentBag 인스턴스로 래핑하여 사용한다.
실제 PersistentBag 클래스를 살펴보면 List 인터페이스를 구현하고 있으며, 내부에 List<E> 타입의 실제 컬렉션 객체 bag를 관리하고 있다. 생성자에서는 Collection<E> 타입의 인자를 받아 bag 필드를 초기화하는 것을 확인할 수 있다. 이때 부모 클래스인 AbstractPersistentCollection<E>의 setInitialized() 메소드를 호출하여 PersistentBag 객체가 초기화되었는지 여부를 관리한다.
@Incubating
public class PersistentBag<E> extends AbstractPersistentCollection<E> implements List<E> {
protected List<E> bag;
//...
public PersistentBag(SharedSessionContractImplementor session, Collection<E> coll) {
super( session );
providedCollection = coll;
if ( coll instanceof List ) {
bag = (List<E>) coll;
}
else {
bag = new ArrayList<>( coll );
}
setInitialized();
setDirectlyAccessible( true );
}
//...
}public abstract class AbstractPersistentCollection<E> implements Serializable, PersistentCollection<E> {
//...
private boolean initialized; //객체의 초기화 여부 관리
private transient boolean initializing; //객체가 초기화 중인지 여부 관리
protected final void setInitialized() {
this.initializing = false;
this.initialized = true;
}
//...
}
실제 컬렉션 초기화전에는 isInitialized() 결과가 false인 반면 컬렉션 객체에 직접 접근하여 초기화된 이후에는 반환값이 true가 되는 것을 확인할 수 있다.



자 그럼 정리해보자. @OneToMany 연관관계를 가진 엔티티는 분명 연관관계의 주인이 아님에도 불구하고 엔티티 조회 시 lazy 로딩이 동작한다. 외래키를 직접 관리하지 않으므로 @OneToOne 매핑에서 처럼 eager 로딩으로 동작해야 하는거 아니야? 싶겠지만, @OneToMany로 매핑되는 컬랙션 객체는 하이버네이트에서 기본적으로 PersistentBag 객체로 초기화된다. 해당 객체는 내부적으로 bag라는 필드 변수를 두어 실제 매핑되는 객체를 관리하며 initialized라는 변수로 초기화 여부를 관리한다.
PersistentBag 객체가 결국 프록시 객체 아니야? 싶겠지만, @OneToMany 관계에서 fetch = FetchType.EAGER 로 설정되어 있어도 항상 실제 객체가 아닌 PersistentBag 객체로 조회된다. @OneToOne 관계가 EAGER로 설정되어 있을 땐 실제 클래스 객체로 조회되는 것과 차이가 있는 것이다. 즉 @OneToMany 관계에서는 일관되게 컬렉션 객체가 PersistentBag 객체로 초기화 되며 내부적으로 bag, initialized 필드로 상태를 표현할 수 있기 때문에 lazy 로딩이 제대로 동작하는 것이다.
양방향 @OneToOne에서의 LAZY 로딩 문제 해결 방법
그렇다면 양방향 @OneToOne의 연관관계 주인이 아닌 엔티티 조회 시 eager 로딩되는 문제를 어떻게 해결해야 할까??
일단 정말 양방향 연관관계가 필요한 것이 아니라면 단방향 연관관계로 변경하는 것이다. 앞서 언급한 예제에서 UserProfile, UserPrivacy 엔티티 내 User 엔티티에 대한 매핑만 남기고 User 엔티티 내의 UserProfile, UserPrivacy 엔티티에 대한 연관관계는 삭제하는 것이다.
만약 양방향 연관관계가 정말 필요하다면 불필요한 select 쿼리가 여러번 발생하지 않도록 항상 fetch join해서 조회하는 것이다. 아래와 같이 아예 findById 메소드를 오버라이딩하여 불필요한 select 쿼리 3번을 1번만 발생하도록 수정할 수 있다.
@Query("""
select u
from User u
join fetch UserProfile up on up.user.id = u.id
join fetch UserPrivacy upv on upv.user.id = u.id
where u.id = :userId
""")
Optional<User> findById(@Param("userId") String userId);
다음 방법은 억지로 양방향 @OneToOne 관계를 @OneToMany - @ManyToOne 매핑 관계로 변경하는 방법이 있다고 하는데(이 경우 매핑되는 컬렉션 객체의 크기는 항상 1), 굉장히 오버스러운 해결방안인 것 같다. 빈대 잡으려다 초가삼간 다 태우는 느낌쓰...
optional = false
또한 어떤 글에서는 다음과 같이 매핑을 optional = false로 설정하여 연관관계가 항상 존재함을 보장함으로써 null이 아닌 항상 프록시 객체로 조회되도록 하는 방법을 소개하고 있었다. 그러나 해보면 알겠지만 이는 당연히 제대로 동작하지 않는다. 그 이유는 너무 당연한데, 영속성 컨텍스트에서 관리되는 객체는 (실제 객체이든, 프록시 객체이든) 엔티티 타입과 id를 무조건 알고 있어야 하기 때문이다.
즉 User 엔티티의 연관관계를 optional = false로 설정한다 한들 UserProfile, UserPrivacy 프록시 객체의 id를 알아야 하고, 이를 알기 위해서는 user_profile, user_privacy 테이블을 조회할 수 밖에 없다. 즉 optional = false는 올바른 해결 방법이 아니며, 참고로 user_profile, user_privacy 테이블의 user_id FK를 not null로 설정해도 당연히 lazy 로딩이 동작하지 않는다. 다음 글을 참고하면 좋을 것 같다.
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class User extends BaseTimeEntity {
@OneToOne(mappedBy = "user", fetch = FetchType.LAZY, optional = false)
private UserProfile userProfile;
@OneToOne(mappedBy = "user", fetch = FetchType.LAZY, optional = false)
private UserPrivacy userPrivacy;
}
optional = false + @MapsId
연관 엔티티가 항상 존재함을 보장하면서 연관 엔티티의 id를 자식 테이블에 대한 조회 없이 알 수만 있다면, 양방향 @OneToOne에서 lazy 로딩이 제대로 동작할 것이다. 다음으로 소개하는 방법은 경우에 따라 올바른 해결책일 수 있다. 바로 @MapsId 어노테이션을 이용하여 부모 테이블의 PK를 자식 테이블의 PK로 그대로 사용하는 것이다. 다시 말하지만 양방향 @OneToOne에서 lazy 로딩이 동작하지 않는 이유는 연관관계 주인이 아닌 엔티티, 즉 부모 테이블 조회 시 연관된 자식 테이블의 id를 모르기 때문인데, @MapsId로 자식 테이블에서 부모 테이블의 PK를 id로서 사용하겠다고 선언했기 때문에 이 경우에는 lazy 로딩이 제대로 동작한다.
조금 억지 예제이긴 하지만 team - member 엔티티를 다음과 같이 @OneToOne으로, team 테이블의 pk를 member 테이블의 pk로 사용하도록 정의해보자. 생성된 member 테이블의 member_id 컬럼은 PK이면서 team 테이블에 대한 FK이다.
@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Team {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "team_id")
private Long id;
private String name;
@OneToOne(mappedBy = "team", fetch = FetchType.LAZY, optional = false)
Member member;
}@Getter
@Builder
@AllArgsConstructor
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Member {
@Id
private Long id; //@GeneratedValue 어노테이션을 선언해줄 필요 없음
private String name;
@MapsId
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Team team;
}create table member (
member_id bigint not null,
name varchar(255),
primary key (member_id)
) engine=InnoDB
create table team (
team_id bigint not null auto_increment,
name varchar(255),
primary key (team_id)
) engine=InnoDB
alter table member
add constraint FK417p227iw2xgj6derejje8xd1
foreign key (member_id)
references team (team_id)
위와 같이 설정하면, Team 엔티티 조회 시 연관된 Member 엔티티가 항상 존재하여(optional = false로 설정했기 때문), team 객체 내 member 변수를 프록시 객체로 초기화하며, 또한 Member 엔티티의 id는 Team 엔티티의 id와 같음을 이미 알고 있으므로(@MapsId로 설정했기 때문) member 테이블에 대한 추가적인 select 없이 lazy 로딩이 가능한 것이다. 실제 조회된 team 객체의 연관된 member의 클래스 타입은 HibernateProxy 이다.

그러나 해당 방법은 특정 테이블의 PK를 다른 테이블의 PK로 재활용하기 때문에 테이블 구조의 변경에 유연하지 못한 설계이다. 예를 들어 기존 team - member 관계가 현재는 1:1이지만 이는 1:N으로 변경된 여지가 충분히 있다. 해당 변경으로 인해 member 테이블은 더이상 team 테이블의 id를 PK로 사용할 수 없게 된다. 애초에 member 테이블만의 PK를 관리하고 있었다면 매핑관계가 변경되더라도 전체 구현에 영향이 없을 것이다. 즉 optional = false + @MapsId 해결방안은 연관관계가 1:1로 고정되어 변경될 가능성이 0%인 경우에만 적용할 수 있는 방법이다.
지금까지 양방향 @OneToOne 관계에서 연관관계 주인이 아닌 엔티티 조회 시 lazy 로딩이 제대로 동작하지 않는 원인 및 해결방안과 이를 이해하기 위해 하이버네이트의 프록시에 대해 알아보았다. 프로젝트 초반에는 user 테이블에 user_profile, user_privacy 테이블의 데이터까지 모두 때려 넣었었다. 그러나 User는 특히나 인증, 인가 로직 등에서 매우 많이 조회되는 엔티티이며, 각 데이터의 특징도 달라 DB 정규화를 진행하여 테이블로 분리한 것인데, 양방향 매핑관계가 추가되면서 정규화가 무색할 만큼 불필요한 쿼리가 많이 발생하게 되었다.
아무튼 JPA 은근 까다로운 기술인 것 같다. 아무 생각 없이 추가한 매핑관계가 이미 적용한 최적화까지 무색하게 할 만큼... JPA 다시 공부하자.
끝.
참고
The best way to map a @OneToOne relationship with JPA and Hibernate - Vlad Mihalcea
Learn the best way to map a OneToOne association with JPA and Hibernate when using both unidirectional and bidirectional relationships.
vladmihalcea.com
OneToOne 관계는 과연 지연로딩이 되는가?
JPA 연관관계 매핑 - @OneToOneJPA 프록시즉시로딩과 지연로딩이란?OneToOne 은 즉시로딩인가 지연로딩인가JPA에서 단방향 매핑은 @JoinColumn과 @OneToOne 를 통해 할 수 있다.양방향 매핑은 Team Class에 Member
velog.io
[DB] 프로젝트 데이터베이스 모델링 기록
1/ 개념 정리 부모테이블, 자식 테이블 부모 테이블은 다른 테이블과 관계에서 상위에 있는 테이블을 의미한다. 부모 테이블은 주로 기본 데이터를 저장하고, 다른 테이블과의 관계에서 외래 키(
microhabitat.tistory.com
JPA Hibernate 프록시 제대로 알고 쓰기
JPA…
tecoble.techcourse.co.kr
JPA @OneToOne은 FetchType.LAZY가 안 먹힐 수 있다?
JPA에서 @OneToOne 연관관계일 때 지연 로딩이 안 될 수 있다? 이제는 JPA가 상당히 많이 쓰이고 있기도 하고 유명한 모 강의도 있어서 많은 사람들이 잘 알고 쓰고 있긴하다. 그러나 실제 경험해본
jeong-pro.tistory.com
'JPA' 카테고리의 다른 글
| [JPA] 부모 엔티티 삭제 시 FK 제약 조건이 걸린 자식 엔티티 처리 방법 (0) | 2024.01.05 |
|---|
- Total
- Today
- Yesterday
- Transaction
- Java
- mockito
- Git
- 모두의 리눅스
- 디자인 패턴
- 전략 패턴
- Linux
- Front Controller
- facade 패턴
- vscode
- rest api
- spring aop
- Spring Security
- QueryDSL
- SSE
- spring boot
- 단위 테스트
- FrontController
- C++
- JPA
- Gitflow
- junit5
- servlet filter
- 서블릿 컨테이너
- Assertions
- github
- 템플릿 콜백 패턴
- ParameterizedTest
- spring
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |